
[컴퓨터 구조] 명령어 파이프라이닝과 주소 지정 방식⭐
▶ 명령어 파이프라이닝
- 정의
- CPU 처리 속도를 높이기 위해 CPU 내부 하드웨어를 여러 단계로 나누어 명령어를 처리하는 병렬 컴퓨팅 기법이다.
- CPU 처리 속도를 높이기 위해 CPU 내부 하드웨어를 여러 단계로 나누어 명령어를 처리하는 병렬 컴퓨팅 기법이다.
- 장점
- 파이프라인을 사용하면 한 명령어의 특정 단계를 처리하는 동안 다른 부분에서는 다른 명령어의 다른 단계를 처리할 수가 있게 되므로 속도가 향상될 수 있다.
▷ 단계별 파이프라이닝
① 2단계 파이프라인
- 정의
- 명령어를 실행하는 하드웨어를 인출 단계(Fetch stage)와 실행 단계(excute stage)로 나눈 것을 말한다.
- 명령어를 실행하는 하드웨어를 인출 단계(Fetch stage)와 실행 단계(excute stage)로 나눈 것을 말한다.
- 특징
- 두 단계에 동일한 클록을 가하여 동작 시간을 일치시킨다.
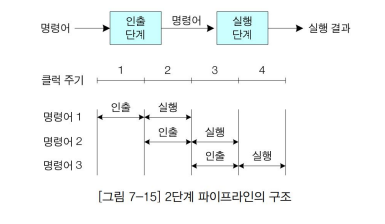 ① 첫 번째 클록 주기에는 인출 단계가 명령어를 인출하고,
② 두 번째 클록 주기에는 인출된 첫 번째 명령어가 실행 단계로 보내져 실행되며, 동시에 인출 단계는 두 번째 명령어를 인출한다. ( 명령어 선인출)
① 첫 번째 클록 주기에는 인출 단계가 명령어를 인출하고,
② 두 번째 클록 주기에는 인출된 첫 번째 명령어가 실행 단계로 보내져 실행되며, 동시에 인출 단계는 두 번째 명령어를 인출한다. ( 명령어 선인출) - 소요 시간이 오래 걸리는 클록 주기로 맞춘다. (클록 : CPU의 속도를 나타내는 단위)
- 두 단계에 동일한 클록을 가하여 동작 시간을 일치시킨다.
- 장점
- 2-단계 파이프라인을 이용하면 명령어 처리 속도가 최대 두 배만큼 빨라진다.
- 첫 번째 명령어는 2단계의 소요 시간이 걸리긴 하지만, 다음 명령어부터는 한 클럭씩 밖에 걸리지 않아 소요 시간이 줄어든다. (1클럭으로 개선)
- 문제점
- 두 단계의 처리 시간이 동일하지 않으면 두 배의 속도 향상을 얻지 못해 파이프라인 효율이 저하된다.
(소요 시간이 오래 걸리는 클록 주기로 맞추기 때문)
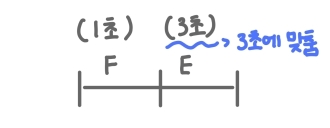
- 두 단계의 처리 시간이 동일하지 않으면 두 배의 속도 향상을 얻지 못해 파이프라인 효율이 저하된다.
(소요 시간이 오래 걸리는 클록 주기로 맞추기 때문)
- 해결책
- 파이프라인 단계를 세분화하여, 각 단계의 처리 시간을 (거의) 같아지도록 한다.
- 파이프라인 단계를 세분화하여, 각 단계의 처리 시간을 (거의) 같아지도록 한다.
② 4단계 파이프라인
- 특징
- 명령어 하나를 수행하기 위해 4단계를 거쳐야 한다.
- 명령어 하나를 수행하기 위해 4단계를 거쳐야 한다.
- 구성 단계
- 명령어 인출(IF) 단계
- 명령어 해독(ID) 단계
- 오퍼랜드 인출(OF) 단계
- 실행(EX) 단계
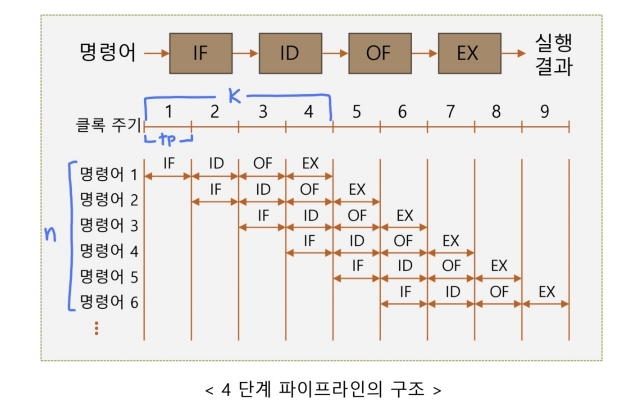
- 장점
- 파이프라인 단계의 수를 증가시켜 전체적으로 속도 향상 개선할 수 있다.
- 첫 번째 명령어는 4단계의 소요 시간이 걸리긴 하지만, 다음 명령어부터는 한 클럭씩밖에 걸리지 않아 소요 시간이 줄어든다.
▷ 파이프라인의 효율성

- 파이프라인에 의한 전체 명령어 실행 시간 T
- 첫 번째 명령어를 실행하는데 k 주기가 걸리고, 나머지 (n - 1) 개의 명령어들은 각각 한 주기씩만 소요
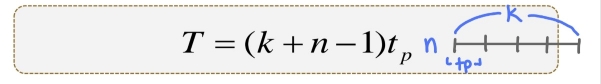
- 첫 번째 명령어를 실행하는데 k 주기가 걸리고, 나머지 (n - 1) 개의 명령어들은 각각 한 주기씩만 소요
- 속도 향상률
- n(명령어)의 숫자가 커질수록 k배에 가까워진다.
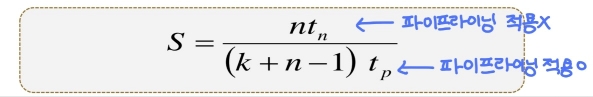
- n(명령어)의 숫자가 커질수록 k배에 가까워진다.
- 파이프라인에 의한 최대 속도 향상률은 파이프라인의 주기수 k이다. (최대 k배만큼 빨라진다.)
- 즉, 4단계 파이프라이닝을 하면 최대 4배만큼 빨라진다!(저해 요소 배제 시)
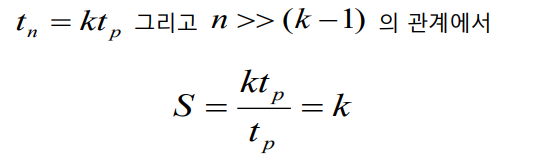
- 즉, 4단계 파이프라이닝을 하면 최대 4배만큼 빨라진다!(저해 요소 배제 시)
- 예제

- 파이프라인 효율 저하 요인
- 모든 명령어들이 파이프라인 단계를 전부 거치지는 않는다.
- 어떤 명령어에서는 오퍼랜드를 인출할 필요가 없지만, 파이프라인의 하드웨어를 단순화시키기 위해서는 모든 명령어가 네 단계들을 모두 통과하도록 해야 한다.
- 어떤 명령어에서는 오퍼랜드를 인출할 필요가 없지만, 파이프라인의 하드웨어를 단순화시키기 위해서는 모든 명령어가 네 단계들을 모두 통과하도록 해야 한다.
- 파이프라인의 클럭은 처리시간이 가장 긴 단계 기준이 된다.
- 두 단계에서 동시에 기억장치 액세스하는 경우 기억장치 충돌이 일어나 지연이 발생한다.
- IF 단계와 OF 단계가 동시에 기억장치를 액세스하는 경우이다.
- IF 단계와 OF 단계가 동시에 기억장치를 액세스하는 경우이다.
- 조건 분기 명령어가 실행되면, 미리 인출하여 처리하던 명령어들이 무효화된다.
- 분기가 발생한 주소로 이동해야하기 때문이다.
- 모든 명령어들이 파이프라인 단계를 전부 거치지는 않는다.
▶ 주소 지정 방식
- 정의
- 연산에 사용될 데이터를 주기억장치의 어떤 위치에서 인출할 것인가를 미리 명령어 형식의 오퍼랜드 주소부에 지정하는 방식
- 연산에 사용될 데이터를 주기억장치의 어떤 위치에서 인출할 것인가를 미리 명령어 형식의 오퍼랜드 주소부에 지정하는 방식
- 다양한 주소 지정 방식을 사용하는 이유
- 제한된 수의 명령어 비트들을 이용하여 여러가지 방법으로 오퍼랜드를 지정하고, 더 큰 용량의 기억장치를 사용하기 위함
▷ 즉시 주소 방식
- 정의
- 데이터가 명령어에 포함되어 있는 방식
- 오퍼랜드 필드의 내용이 연산에 사용될 실제 데이터이다. (주소 번지를 지칭하는 것이 아님)
- ex. LOAD 7인 경우, 7이 번지가 아닌 7값을 로드해라 라는 의미
- ex. LOAD 7인 경우, 7이 번지가 아닌 7값을 로드해라 라는 의미
- 장점
- 메모리에 액세스 필요 없어 비교적 빠르다.
- 그냥 그 수를 넘겨주면 되기 때문이다.
- 그냥 그 수를 넘겨주면 되기 때문이다.
- 메모리에 액세스 필요 없어 비교적 빠르다.
- 단점
- 표현 가능한 데이터 크기(사용할 수 있는 수)가 오퍼랜드 필드의 비트 수로 제한된다.
- 비트 안에서 표현된 수를 세트해주는 것이기 때문이다.
- 표현 가능한 데이터 크기(사용할 수 있는 수)가 오퍼랜드 필드의 비트 수로 제한된다.
▷ 직접 주소 방식
- 정의
- 오퍼랜드 필드의 내용이 유효 주소(EA, Effective Address)가 되는 방식
- 유효주소 : 데이터(피연산)가 저장된 메모리 실제 주소
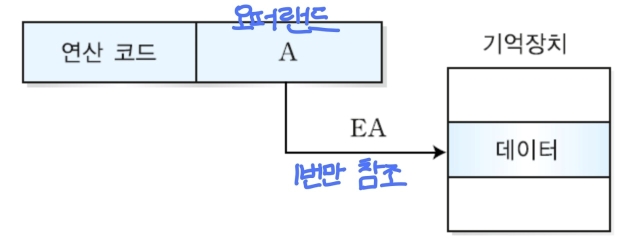
- 유효주소 : 데이터(피연산)가 저장된 메모리 실제 주소
- 오퍼랜드 필드의 내용이 유효 주소(EA, Effective Address)가 되는 방식
- 장점
- 데이터 인출을 위해 한 번의 기억장치 액세스만 필요하다. (1번만 참조)
- 필드에 유효 주소가 바로 있기 때문이다.
- 필드에 유효 주소가 바로 있기 때문이다.
- 데이터 인출을 위해 한 번의 기억장치 액세스만 필요하다. (1번만 참조)
- 단점
- 표현 가능한 데이터 크기(사용할 수 있는 수)가 오퍼랜드 필드의 비트 수로 제한된다.
▷ 간접 주소 방식
- 정의
- 오퍼랜드 필드의 내용이 유효주소를 가리키는 주소를 저장하는 방식 (메모리 처음 접근시 유효주소 x)
- 즉, 오퍼랜드가 지칭한 메모리 주소로 갔을 때 또 다른 주소 값 지칭한다.
- mode bit i를 통해 간접인지 직접인지 알 수 있다 : i=0 직접, i=1 간접)
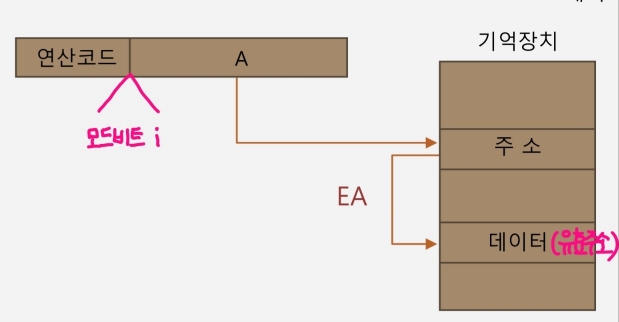
- 오퍼랜드 필드의 내용이 유효주소를 가리키는 주소를 저장하는 방식 (메모리 처음 접근시 유효주소 x)
- 장점
- 기억장치에 있는 비트만큼 주소를 참조할 수 있기 때문에 더 긴 주소 저장 가능하다.
- 기억장치에 있는 비트만큼 주소를 참조할 수 있기 때문에 더 긴 주소 저장 가능하다.
- 단점
- 액세스 시간이 길어진다.
▷ 레지스터 주소 지정 방식
- 정의
- 연산에 사용될 데이터가 레지스터에 저장되어 있는 방식
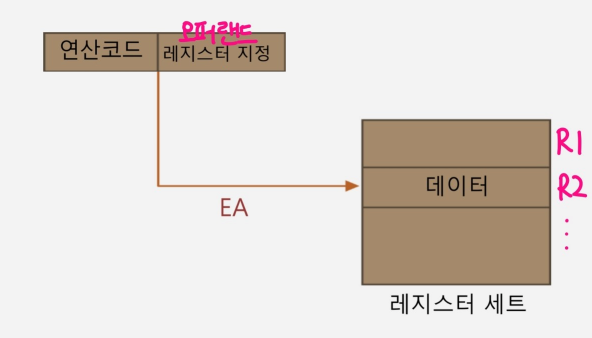
- 연산에 사용될 데이터가 레지스터에 저장되어 있는 방식
- 장점
- 오퍼랜드 필드의 비트 수 적어도 괜찮다.
- 데이터 인출을 위하여 메모리에 접근하지 않고 레지스터에 바로 접근하므로 속도가 빠르다.
- 속도: 즉시 > 레지스터 > 직접 > 레지스터 간접 > 간접
- 속도: 즉시 > 레지스터 > 직접 > 레지스터 간접 > 간접
- 단점
- 데이터 저장 공간이 CPU 내부 레지스터로 제한되어있다.
- 레지스터 수 자체가 제한되어 있기 때문에 많이 참조할 수 없다.
▷ 레지스터 간접 주소 지정 방식
- 정의
- 오퍼랜드 필드(레지스터 번호)가 가리키는 레지스터의 내용을 유효 주소로 사용하여 실제 데이터를 인출하는 방식
- 레지스터를 거친 다음 간접 주소로 가는 것이다.
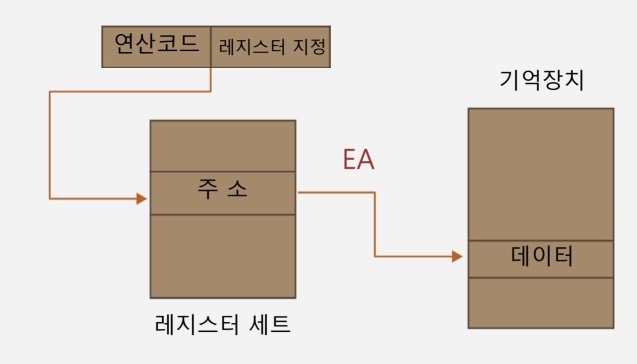
- 레지스터를 거친 다음 간접 주소로 가는 것이다.
- 오퍼랜드 필드(레지스터 번호)가 가리키는 레지스터의 내용을 유효 주소로 사용하여 실제 데이터를 인출하는 방식
▷ 인덱스 주소 지정 방식
-
정의
- 인덱스 레지스터의 값과 변위⭐를 더하여 유효 주소를 결정 (실제 데이터가 있는 피연산자를 결정)하는 방식
- 인덱스 레지스터는 배열의 시작번지를 참조한다.
- 데이터 배열이 기억장치에 35번부터 저장되어 있고, 인덱스 레지스터의 내용이 345일 경우 아래와 같다.
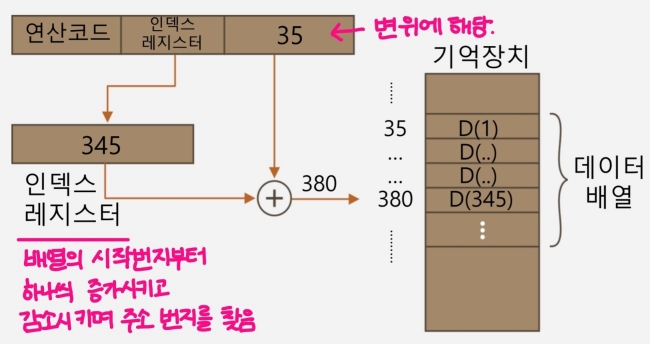
- 데이터 배열이 기억장치에 35번부터 저장되어 있고, 인덱스 레지스터의 내용이 345일 경우 아래와 같다.
-
주요 용도
- 배열 데이터를 엑세스할 때 인덱스 레지스터가 필요하다.
📎참조
- 『 성결대학교 김자원 교수님 』 - 컴퓨터 구조 (2023)
- 『 컴퓨터구조(제5판) 』 - 복두 출판사
- https://ko.wikipedia.org/wiki/%EB%AA%85%EB%A0%B9%EC%96%B4_%ED%8C%8C%EC%9D%B4%ED%94%84%EB%9D%BC%EC%9D%B8
댓글남기기