
[Network] #9 네트워크 계층과 IP 주소
[혼자 공부하는 네트워크↗️], 컴퓨터 네트워킹: 하향식 접근 (제8판)을 바탕으로 정리한 글입니다.
- 지난 포스팅에서 같은 네트워크 내에 호스트끼리 정보를 주고 받기 위해 케이블, 허브, 스위치 같은 장비를 학습했다.
- 이번 포스팅에는 LAN을 넘어 다른 네트워크와 속한 호스트와 패킷을 주고받을 수 있게 하는 “네트워크 계층”에 대해 학습해보자.
1. 물리 계층과 데이터링크 계층의 한계
물리 계층과 데이터 링크 계층만으로는 LAN을 넘어서 통신하기 어려운데, 그 이유는 아래와 같다.
① 다른 네트워크까지의 도달 경로를 파악하기 어렵다.
- 지구 반대편에 있는 친구와 패킷을 주고받는다고 가정하자. 이 경우는 네트워크 간 통신이 이루어지기 때문에 패킷이 여러 네트워크를 거쳐 이동할 것이다.
- 이때, 패킷이 어떤 경로로 이동해야 최적인지를 물리 계층과 데이터링크 계층의 기술 만으로는 판단하기 어렵다.
- 따라서 네트워크 계층의 라우팅(routing)으로 패킷이 이동할 최적의 경로를 결정해야 한다.
- 라우터(router)는 라우팅을 수행하는 대표적인 장비를 의미한다.
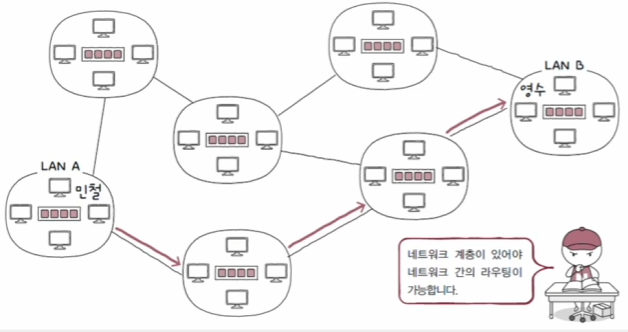
② 모든 네트워크에 속한 모든 호스트의 위치를 특정하기 어렵다.
- MAC 주소는 기본적으로 네트워크 인터페이스마다 부여가 되는데, 호스트는 시시때때로 속해있는 네트워크가 얼마든지 달라질 수도 있기 때문에, MAC 주소 하나만으로 모든 네트워크에 속한 모든 호스트의 위치를 특정하기 어렵다.
- e.g., 집에서 Wi-Fi를 사용하다가 회사에서는 셀룰러 데이터를 사용 -> 집의 네트워크에서 사용하던 MAC 주소는 회사 네트워크에선 더 이상 유효하지 않음.
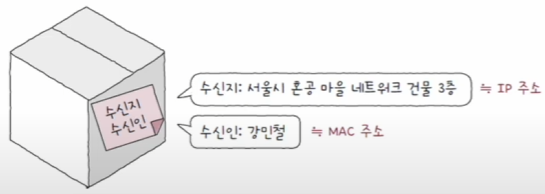
- 이러한 MAC 주소의 한계(로컬 네트워크 내에서만 유효)를 극복하기 위해 사용되는 네트워크 주소 체계를 IP 주소라고 한다.
- MAC 주소와 IP 주소는 함께 사용되고, 기본적으로 IP 주소를 우선 활용한다.
| MAC 주소 | IP 주소 |
|---|---|
| 택배의 수신인 역할 | 택배의 수신지 역할 |
| 물리 주소 | 논리 주소 |
| NIC마다 할당되는 고정된 주소 | - 유동적으로 할당 - 자동으로 할당 받거나 사용자가 직접 할당 |
2. IPv4
IP(Internet Protocol)이란, 물리 계층과 데이터 링크 계층의 한계를 극복하는 프로토콜이다.
2.1 IPv4 주소
IPv4 주소는 32비트(4바이트)로 구성되어 있으며, 4개의 10진수 숫자로 표현된다. (e.g.,
192.168.1.1)
- 즉,
2^32만큼 (약 43억)표현이 가능하다.- 전 세계 인구가 하나씩 IP 주소를 가지고 있어도 부족한 숫자이다.
- IPv4의 주소 고갈 문제를 해결하기 위해 IPv6 등장했다. (뒤에 설명)
- 숫자당 8비트씩(2^8) 끊어서 표시되며, 0-255 범위 안에 있는 네 개의 10진수로 표기한다.
- 8비트로 표현할 수 있는 값의 범위는 00000000(0)부터 11111111(255)까지이다.
- 각각의 숫자는 점(.)으로 구분하는데, 이 점으로 구분된 각각의 숫자를 옥텟(octet)이라고 한다.
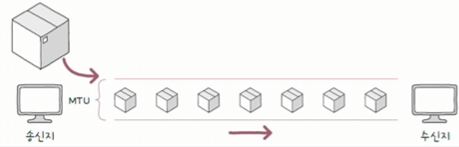
2.2 단편화
단편화(Fragmentation)는 큰 데이터를 MTU(Maximum Transmission Unit) 크기에 맞춰 작은 패킷으로 나누는 과정이다.
-
MTU(Maximum Transmission Unit)란?
- 한 번에 전송 가능한 IP 패킷의 최대 크기를 의미한다.
- IP 패킷의 헤더도 MTU 크기에 포함된다.
- 일반적으로 MTU 크기는 1500바이트이며, 전송할 데이터가 MTU를 초과하면 데이터를 쪼갠다.
- MTU 크기 이하로 나누어진 패킷은 수신지에 도착하면 다시 재조합된다.
IPv6에서는?
- IPv6는 단편화를 경로 상의 네트워크 장비에서 처리하지 않는다.
- 대신, 송신측이 미리 Path MTU Discovery를 사용해 경로상의 MTU를 확인하고, 적절한 크기로 데이터를 조정한다.
- 비유하자면, IPv6는 미리 상자의 크기를 조사해, 처음부터 문 크기(MTU)에 맞는 작은 상자로 나눠 보내는 것과 같다.
이더넷 프레임에서 페이로드에 명시할 수 있는 일반적인 데이터 크기는 1500바이트로 제한되어 있는 이유는, 데이터 부분의
IPv4 패킷 헤더 + IPv4 패킷 페이로드보다 커지면 단편화가 이루어지기 때문이다.
- MTU를 넘는 큰 데이터를 보내려면 나눠야 하므로, 단편화를 피하기 위해 1500바이트 이하로 맞추는 것이 일반적이다.
- 아래 그림의 데이터 부분(IPv4 패킷 헤더 + IPv4 패킷 페이로드)이 IPv4의 패킷 구조이다.
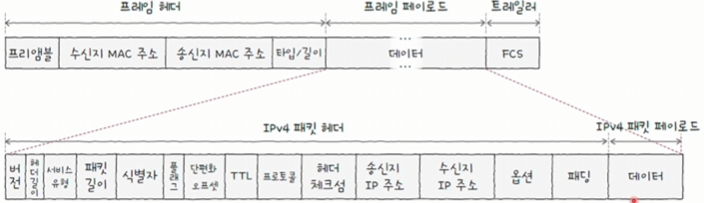
2.3 IPv4 패킷의 핵심 필드
IPv4 패킷의 핵심 필드는 1)식별자, 2)플래그, 3)단편화 오프셋, 4)TTL, 5)프로토콜, 6)송신지 IP 주소, 7)수신지 IP 주소 가 존재한다.
- 1)식별자, 2)플래그, 3)단편화 오프셋 필드를 기준으로 단편화가 이루어진다.
- 6)송신지 IP 주소, 7)수신지 IP 주소 필드를 기준으로 주소 지정이 이루어진다.
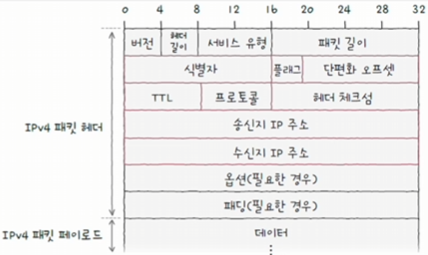
2.3.1 식별자(identifier)
패킷에 할당된 고유한 번호가 명시가 된다.
쪼개져서 도착한 IPv4 패킷들이 어떤 메시지에서 쪼개졌는지를 알기 위해 사용된다.
2.3.2 플래그(flag)
세 개의 비트로 구성되어 있는 필드를 말한다.
- 첫 번째 비트는 항상 0으로써 현재 사용되지 않으며, 실질적으로 사용되는 비트는 아래와 같다.
- DF 비트(Don’t Fragment): IP 단편화 수행여부를 나타냄
- 1이라면: IP 단편화 수행하지 말것
- 0이라면: IP 단편화 가능하다
- MF 비트(More Fragment): 단편화된 패킷이 더 있는지를 나타냄
- 1이라면: 쪼개진 패킷이 아직 더 있다.
- 0이라면: 이 패킷이 마지막 패킷이다

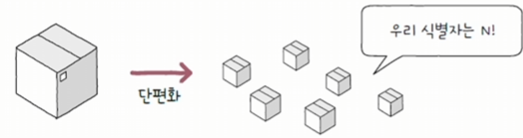
2.3.3 단편화 오프셋(fragment offset)
초기 데이터에서 몇 번째로 떨어진 패킷인지를 나타내는 필드를 말한다.
- 단편화되어 전송되는 패킷들은 수신지에 순서대로 도착하지 않을 수 있다.
- 수신지가 패킷들을 순서대로 재조합하려면 단편화된 패킷이 초기 데이터에서 몇 번째에 해당하는 패킷인지 알아야 한다.
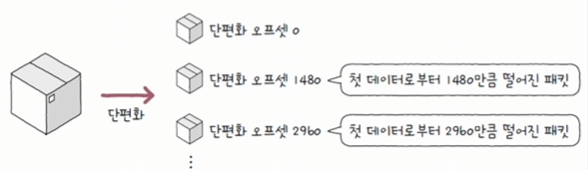
2.3.4 TTL(Time to Live)
패킷의 수명을 나타내는 필드를 말한다.
- 무의미한 패킷이 네트워크상에 지속적으로 남아있는 것을 방지하기 위해 존재한다.
- 패킷(데이터그램)이 하나의 라우터를 거칠 때마다 TTL 값이 1씩 감소하며, TTL이 0이 되면 폐기된다.
- 홉(hop): 패킷이 호스트 또는 라우터에 한 번 전달되는 것을 말한다.
- 즉, TTL 필드는 홉마다 1씩 감소되는 값이라고 볼 수 있다.
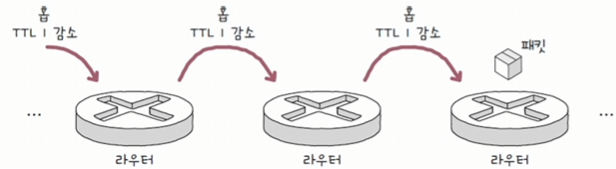
- 즉, TTL 필드는 홉마다 1씩 감소되는 값이라고 볼 수 있다.
2.3.5 헤더 체크섬
헤더 체크섬은 IP 데이터그램의 헤더 오류 검출에 사용되며, 라우터는 오류가 발견된 데이터그램을 폐기한다.
- TTL 및 옵션 필드는 각 라우터에서 변경되므로, 체크섬은 매번 재계산되어야 한다.
- 네트워크 계층(IP)과 전송 계층(TCP/UDP)에서 각각 오류 검사를 수행하는 이유는:
- IP 계층은 헤더만 검사(데이터는 제외)하고,
- TCP/UDP 체크섬은 전체 세그먼트(헤더와 데이터)를 검사한다.
- TCP/UDP는 IP 프로토콜에 의존하지 않아서, IP가 아닌 다른 프로토콜 위에서도 동작할 수 있다.
2.3.6 프로토콜
상위 계층의 프로토콜이 무엇인지를 나타내는 필드이다.
- 이 필드는 일반적으로 IP 데이터그램이 최종 목적지에 도착했을 때만 사용된다.
- 무엇을 캡슐화했는지를 프로토콜 필드에 명시한다.
- e.g., 전송 계층의 대표적인 프로토콜인 TCP는 6번, UDP는 17번
2.3.6 송/수신지 IP 주소
이름 그대로 송/수신지의 IPv4 주소를 의미한다.
3. IPv4 주소의 구조와 클래스풀 주소 체계
3.1 IPv4 주소의 구조
IP 주소의 구조는 어떻게 구성되는지 살펴보자.
- IP 주소의 구조는 크게 네트워크 주소와 호스트 주소로 구성된다.
- 네트워크 주소: 호스트가 속한 네트워크를 식별.
- 호스트 주소: 네트워크 내에서 개별 호스트를 식별.

IP 주소에서 네트워크 주소와 호스트 주소 크기는 각각 어느 정도가 적당할까?
그때그때 다르다! 네트워크 주소에 상대적으로 많은 비트를 할당할 수도 있고, 적은 비트를 할당할 수도 있기 때문이다.
- 아래 그림처럼 호스트 주소가 큰 경우, 한 네트워크당 호스트 할당에 24비트를 사용할 수 있다.
- 즉, 상대적으로 많은 호스트에 IP 주소를 할당할 수 있다.
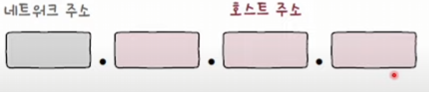
- 아래 그림처럼 네트워크 주소가 큰 경우, 한 네트워크당 호스트 할당에 8비트를 사용할 수 있다.
- 즉, 상대적으로 적은 호스트에 IP 주소를 할당할 수 있다.

- 무조건 호스트 주소 공간을 크게 할당하면?
- 호스트가 할당되지 않은 다수의 IP 주소가 낭비된다.
- 무조건 호스트 주소 공간을 작게 할당하면?
- 호스트가 사용할 IP 주소가 부족해진다.
- 호스트가 사용할 IP 주소가 부족해진다.
즉, 이런 고민을 해결하기 위해 IP 주소의 클래스(class) 라는 개념이 도입되었다.
3.2 클래스풀 주소 체계
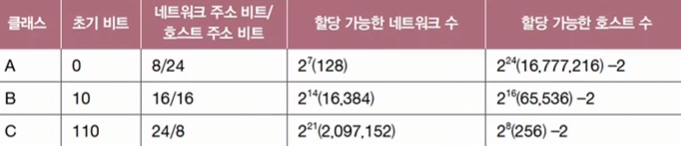
클래스풀 주소 체계란, IP 주소를 네트워크 크기에 따라 A, B, C, D, E 클래스로 나누어 관리하는 방식을 의미한다.
- IP 주소 지정에 사용되는 실질적인 클래스는 A클래스, B클래스, C클래스이다.
- 각 클래스마다 네트워크 주소를 표현하는 크기가 다르기 때문에, 필요한 호스트 IP 개수에 따라 클래스를 달리 선택하여 네트워크 크기를 조정할 수 있다.
- 라우터는 첫 번째 비트들을 보고 해당 주소가 어느 클래스에 속하는지 판별하고, 그에 따라 라우팅 작업을 수행한다.
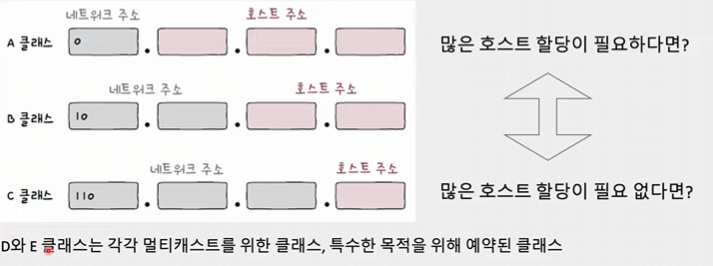
| 특징 | A 클래스 | B 클래스 | C 클래스 |
|---|---|---|---|
| 주소 범위 | 0.0.0.0 - 127.255.255.255 |
128.0.0.0 - 191.255.255.255 |
192.0.0.0 - 223.255.255.255 |
| 첫 번째 옥텟 범위 | 0 - 127 |
128 - 191 |
192 - 223 |
| 네트워크 주소 비트 | 8비트 (첫 번째 옥텟) | 16비트 (첫 두 옥텟) | 24비트 (첫 세 옥텟) |
| 호스트 주소 비트 | 24비트 | 16비트 | 8비트 |
| 네트워크 수 | 2^7 = 128개 |
2^14 = 16,384개 |
2^21 = 2,097,152개 |
| 각 네트워크의 호스트 수 | 2^24 - 2 ≈ 16,777,214개 |
2^16 - 2 = 65,534개 |
2^8 - 2 = 254개 |
| 기본 서브넷 마스크 | 255.0.0.0 (또는 /8) |
255.255.0.0 (또는 /16) |
255.255.255.0 (또는 /24) |
| 주 용도 | 대규모 네트워크 (예: 대형 ISP) | 중간 규모 네트워크 (예: 기업) | 소규모 네트워크 (예: 가정, 소규모 기업) |
3.3 A클래스 (대규모 네트워크)
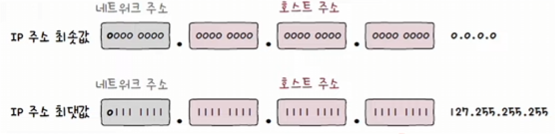
네트워크 주소는 비트
0으로 시작하는 1옥텟 (0-127), 호스트 주소는 3옥텟으로 구성
- 네트워크 수: 2^7 = 128개
- 호스트 수: 각 네트워크당
2^24 - 2(약 1677만 개)

A클래스로 나타낼 수 있는 IP 주소 범위
0.0.0.0 - 127.255.255.255
따라서 가장 처음 옥텟의 주소가 0-127일 경우 A클래스 주소임을 짐작할 수 있다.
3.4 B클래스 (중간 규모 네트워크)
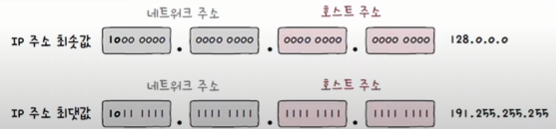
네트워크 주소는 비트
10으로 시작하는 2옥텟(128-191), 호스트 주소는 2옥텟으로 구성
- 네트워크 수: 2^14 = 16,384개
- 호스트 수: 각 네트워크당
2^16 - 2= 65,534개

B클래스로 나타낼 수 있는 IP 주소 범위
128.0.0.0 - 191.255.255.255
따라서, 가장 처음 옥텟의 주소가 128-191일 경우 B클래스 주소임을 짐작할 수 있다.
3.4 C클래스 (소규모 네트워크)
네트워크 주소는 비트
110으로 시작하는 3옥텟(192-223), 호스트 주소는 1옥텟으로 구성
- 네트워크 수: 2^21 = 2,097,152개
- 호스트 수: 각 네트워크당
2^8 - 2= 254개

C클래스로 나타낼 수 있는 IP 주소 범위
192.0.0.0 - 223.255.255.255
따라서, 가장 처음 옥텟의 주소가 192-223일 경우 C클래스 주소임을 짐작할 수 있다.
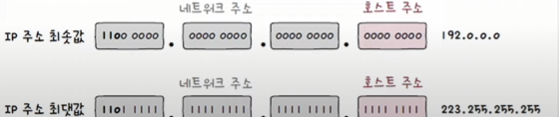
3.5 주소 체계의 예외
호스트의 주소 공간을 모두 사용할 수 있는 것은 아니다.
- 호스트 주소가 전부 0인 IP 주소
- 해당 네트워크 자체를 의미하는 네트워크 주소로 사용된다.
- e.g.,
223.1.1.0
- 호스트 주소가 전부 1인 IP 주소
- 브로드캐스트 주소로 사용된다.
- e.g.,
223.1.1.255
이것이 바로 호스트 IP 주소에 -2를 하는 이유이다.
3.6 클래스별 할당 가능한 주소의 개수 정리
클래스별 할당 가능한 주소의 개수는
-2를 뺀 수와 같다.
호스트 주소의 개수를 계산할 때 네트워크 주소와 브로드캐스트 주소를 제외해야 한다는 의미이다.
3.7 클래스풀 주소 체계의 한계
클래스별 네트워크 크기가 고정되어 있어 여전히 낭비되는 IP 주소가 많을 수 있다.
- A클래스 네트워크 하나 당 할당 가능한 호스트: 1600만개 이상
- B클래스 네트워크 하나 당 할당 가능한 호스트: 6만개 이상
이 IP를 모두 쓰지는 않을 것이다.
그리고 클래스별 네트워크 크기가 고정되어 있어 사전에 정해진 크기 외의 다른 네트워크 구성이 불가능하다.
- C클래스 네트워크 하나 당 할당 가능한 호스트: 254개
- 만약, 직원 300명 컴퓨터를 동일 네트워크로 구성하려면 B클래스 주소를 이용해야 할까?
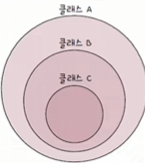
이러한 클래스풀 주소 체계의 한계를 보완하기 위해 “클래스리스 주소 체계” 방식을 주로 사용한다.
4. 클래스리스 주소 체계
4.1 클래스리스 주소 체계란?
클래스리스 주소 체계는 기존의 고정된 클래스(A, B, C) 개념에서 벗어나 네트워크 크기를 더 자유롭게 조정할 수 있는 방식이다.
- 즉, 클래스에 구애받지 않고 네트워크를 나누고 호스트에게 IP 주소 공간을 할당하는 방법이다.
- 오늘날 주로 활용되는 방식이다.
그렇다면 클래스에 구애받지 않고 어떻게 정교하게 네트워크 크기를 나눌 수 있는지 살펴보자.
4.2 서브넷(Subnet)
서브넷은 하나의 IP 네트워크를 여러 개의 작은 네트워크로 분할한 것을 의미한다.
- IP 주소 클래스 할당의 한계점을 극복하기 위해 등장하였다.
- 일반적으로 네트워크라고 부른다.
- 아래 그림에서는 3개의 서브넷이 존재한다.
- 같은 서브넷에 있는 모든 IP 주소는 네트워크 주소가 동일하며, 호스트 주소만 다르다.
- 서브넷은 서브넷 마스크를 통해서 만들어진다.
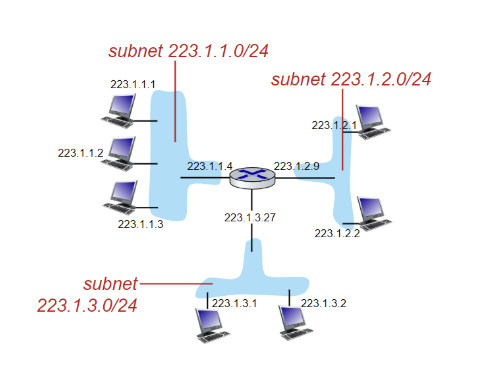
라우터와 스위치에서의 서브넷 관리 및 분할
- 라우터 인터페이스마다 서브넷 하나
- 라우터의 각 인터페이스는 서로 다른 서브넷에 속하며, 인터페이스마다 고유한 IP 대역이 할당
- 스위치는 같은 서브넷에 여러 장치 연결
- 스위치는 하나의 서브넷 내에서 여러 장치를 연결하고, 장치들 간에 직접 통신
- 라우터는 서브넷 분할 및 연결
- 라우터는 서로 다른 서브넷을 연결하고, 서브넷 간의 트래픽을 라우팅
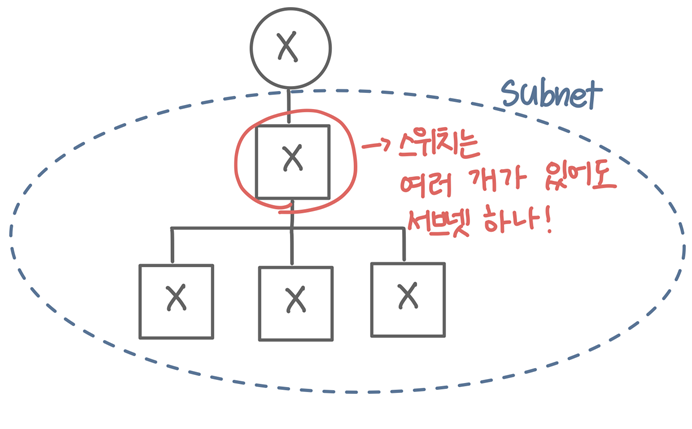
- 라우터는 서로 다른 서브넷을 연결하고, 서브넷 간의 트래픽을 라우팅
4.3 서브넷 마스크(subnet mask)
서브넷 마스크란, IP 주소에서 네트워크 주소와 호스트 주소를 구분하는 비트열을 의미한다.
- 네트워크 주소는 1로, 호스트 주소는 0으로 표기된다.
- “서브넷”이라는 이름 자체가 부분적인 네트워크(서브 네트워크)를 의미하기 때문에, “네트워크 주소와 호스트 주소를 구분하는 비트 열” 이라고 해석하기도 한다.
- 서브넷 마스크를 사용하여 네트워크를 더 세밀하게 나눌 수 있다.
A, B, C 클래스의 기본 서브넷 마스크
- A클래스:
255.0.0.0(11111111.00000000.00000000.00000000) - B클래스:
255.255.0.0(11111111.11111111.00000000.00000000) - C클래스:
255.255.255.0(11111111.11111111.11111111.00000000)
서브넷 마스크 예시
- IP 주소:
192.168.1.0 - 서브넷 마스크:
255.255.255.0(CIDR 표기: /24)- 네트워크 부분: 첫 24비트 (
192.168.1) - 호스트 부분: 마지막 8비트 (0-255)
- 네트워크 부분: 첫 24비트 (
4.4 서브네팅
서브네팅(subnetting)이란, 서브넷 마스크를 이용해 하나의 네트워크를 여러 개의 서브넷으로 나누는 과정이다.
- 여러 개의 서브넷으로 나누면 각 서브넷마다 고유한 네트워크 주소와 호스트 주소 범위를 설정할 수 있다.
- 즉, 서브넷팅을 한다는 것은 네트워크 주소 부분을 더 세분화하는 작업이다. 즉, 호스트 주소 부분을 빼고, 네트워크 주소 부분을 작은 네트워크로 분할하는것이다.
-
서브넷 마스크로 네트워크 주소와 호스트 주소를 구분 짓는 방법에 대해 알아보자
- IP 주소와 서브넷 마스크가 주어졌을 때, 두 값을 이진수로 변환한다.
- 그 후, 비트 AND 연산을 통해 네트워크 주소를 구하면 된다.
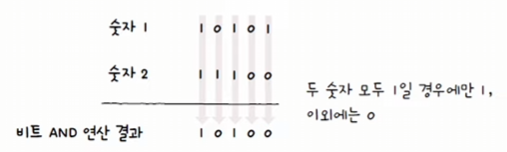
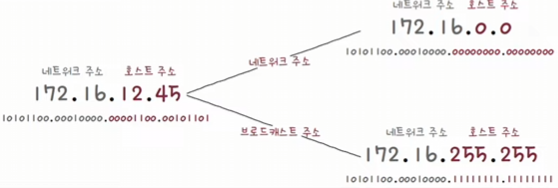
네트워크 주소를 구해보자!
① 아래와 같은 IP 주소와 서브넷 마스크가 있다고 가정

② IP 주소와 서브넷 마스크를 2진수로 변환

③ IP 주소와 서브넷 마스크를 비트 AND 연산
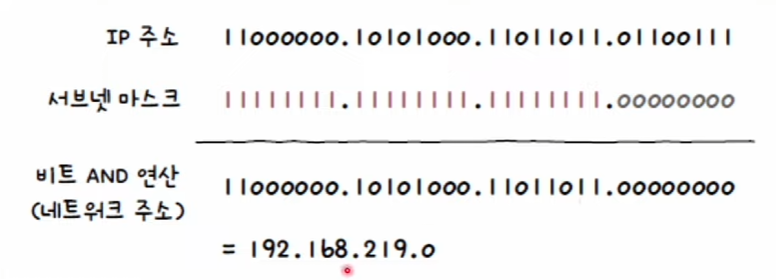
④ 즉, 할당 가능한 호스트 IP 주소의 범위는 아래와 같다.
- 호스트 주소 모두 0: 네트워크 주소:
192.168.219.0 - 호스트 주소 모두 1: 브로드 캐스트 주소:
192.168.219.255 - 호스트 할당 가능 IP 주소:
192.168.219.1-192.168.219.254
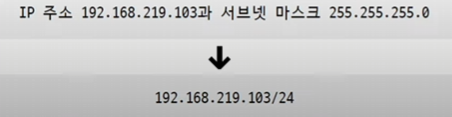
4.5 서브넷 마스크 표기: CIDR 표기법
서브넷 마스크를 표기할 때
255.255.255.0과 같이 10진수로 직접 표기하는 경우도 있지만, “IP 주소/서브넷 마스크상의 1의 개수 형식”으로 표기하는 경우도 많다. 이를 CIDR(Classless Inter-Domain Routing) 표기법이라고 한다.
- CIDR 표기법을 통해 서브넷 마스크를 간편하게 표기할 수 있으며, / 뒤에 1의 개수로 서브넷 크기를 나타낸다.
- e.g.,
- C클래스의 기본 서브넷 마스크는
255.255.255.0, 이를 2진수로 표기하면11111111.11111111.11111111.00000000(1이 총 24개) -> 따라서/24 /24의 경우 서브넷 하나 당 254개의 장치 가능 (2^8 - 2)
- C클래스의 기본 서브넷 마스크는
(복습)
192.168.0.2/25는 어떤 네트워크에 속한 어떤 호스트를 가르킬까?
① 서브넷 마스크 확인
- IP 주소:
192.168.0.2 - CIDR 표기법:
/25/25는 1이 총 25개인 서브넷 마스크를 의미하며, 이를 2진수로 쓰면:11111111.11111111.11111111.10000000- 10진수 서브넷 마스크는
255.255.255.128

② 네트워크 주소 계산
- 네트워크 주소는 IP 주소와 서브넷 마스크를 비트 AND 연산하여 구할 수 있다.
- 192.168.0.2를 2진수로 표현:
11000000.10101000.00000000.00000010 - 서브넷 마스크
/25:11111111.11111111.11111111.10000000 - 비트 AND 연산 결과:
11000000.10101000.00000000.00000000
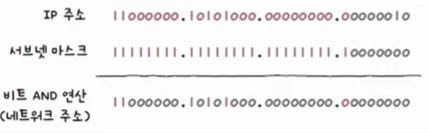
즉, 네트워크 주소는 192.168.0.0
③ 할당 가능한 IP 주소 범위
/25는 총 32비트 중 25비트를 네트워크 부분으로 사용하므로, 남은 7비트는 호스트 비트- 호스트 비트로 표현 가능한 값의 총 개수는
2^7-2= 126- 네트워크 주소:
192.168.0.0 - 브로드캐스트 주소:
192.168.0.127 - 할당 가능 호스트 IP 주소:
192.168.0.126
- 네트워크 주소:
④ 결론
192.168.0.2/25는 총 126개의 호스트를 할당할 수 있는192.168.0.0이라는 네트워크에 속한192.168.0.2를 의미한다.
4.6 주소 블록 획득⭐
주소 블록 획득
- 주소 블록을 획득하는 과정은 주로 IP 주소를 할당받고, 이를 어떻게 관리할 것인지에 대한 과정이다.
- IP 주소 관리를 통해 효율적으로 네트워크를 운영할 수 있다.
- 주소 블록 크기는 서브넷 마스크를 통해 결정된다.
4.6.1 문제1
C클래스 주소 201.222.75.0이 주어졌을 때,
- 10개의 서브넷을 구성하고 서브넷 당 10개의 호스트를 지정하기 위한 서브넷 마스크는 무엇인가
- 201.222.75.100의 주소를 갖는 호스트가 속한 서브넷은 무엇인가?
1)
C클래스의 기본 서브넷 마스크는 /24이다.
10개의 호스트를 지정하려면 2^n≥10, n=4이므로 4비트만큼의 호스트 비트가 필요하다.
따라서 호스트 수는 2^4-2=14개이다. 여기서 2는 브로드캐스트 주소와 네트워크 주소를 제외한 값이다.
또한 10개의 서브넷을 구성하려면 2^n≥10, n=4이므로 4비트만큼의 서브넷 비트가 필요하다.
따라서 기본 서브넷 마스크/24 + 4 = /28이다.
결론적으로 서브넷 마스크는 /28 (255.255.255.240)이다.
2)
먼저 서브넷 범위를 알아야 한다.
따라서 201.222.75.100과 서브넷 마스크 255.255.255.240을 AND연산 해야한다.
201.222.75.100을 2진수로 변환하면 11001001.11011110.01001011.01100100
서브넷 마스크 255.255.255.240을 2진수로 변환하면 11111111.11111111.11111111.11110000이다.
이를 AND 연산 하면 11001001.11011110.01001011.01100000 (201.222.75.96)이다.
따라서 201.222.75.100의 주소를 갖는 호스트가 속한 서브넷은 201.222.75.96/28이다.
4.6.2. 문제2
서브넷 마스크가 255.255.255.192로 주어졌을 때, 한 서브넷에서 호스트에게 할당할 수 있는 IP 주소는 몇 개인가?
서브넷 마스크를 2진수로 변환하면 11111111.11111111.11111111.11000000이다.
이는 CIDR 표기법으로서 서브넷 마스크를 /26으로 표현할 수 있다.
즉, 네트워크 비트는 26비트이고 호스트 비트는 6비트이다.
따라서, 한 서브넷에서 호스트에게 할당할 수 있는 IP 주소는 2^6-2=62이므로 62개이다.
4.6.3 문제3
문제
ISP로부터 주소 블록 200.23.16.0/20을 할당받았다. 이 주소 블록을 8개의 같은 크기의 작은 주소 블록으로 나누고, 각 주소 블록을 8개의 조직(네트워크)로 구성하려고 한다.
풀이
-
서브넷 마스크 계산 (큰 주소 블록 나누기)
200.23.16.0/20주소 블록을 8개의 서브넷으로 나누려고 하므로, 필요한 서브넷 비트 수를 계산해야 한다.2^n ≥ 8을 만족하는 n = 3이므로, 기존 서브넷 마스크 /20에서 3비트를 추가하여 서브넷을 나눈다.- 따라서 서브넷 마스크: /20 + 3 = /23 (255.255.254.0)이다.
- ⚠️ 서브넷팅을 할 때, 기존 네트워크 비트에 추가적인 비트를 더하는 방식으로 서브넷을 나눈다. 따라서 기존 네트워크 비트가 줄어드는 것이 아니라, 서브넷 비트가 늘어나면서 네트워크가 더 작은 단위로 나눠지는 것이다.
-
서브넷 할당
200.23.16.0을 2진수로 변환하면, 11001000.00010111.00010000.00000000이다.-
/20에서 8개의 서브넷을 나누기 위해 3비트를 추가하면, 각 서브넷의 네트워크 주소는 다음과 같다.
서브넷 번호 서브넷 네트워크 주소 1 200.23.16.0/23 2 200.23.18.0/23 3 200.23.20.0/23 4 200.23.22.0/23 5 200.23.24.0/23 6 200.23.26.0/23 7 200.23.28.0/23 8 200.23.30.0/23
서브넷은 2진수에서 마지막 3비트를 변환하면서 각 서브넷 주소가 증가한다.
-
결과
- 서브넷 마스크: /23 (255.255.254.0)
- 할당 가능한 호스트 IP 주소:
2^8-2= 510개 - 총 서브넷 수: 8개 (각 서브넷은 8개의 조직으로 나누어짐)
4.6.4 문제4
문제
C 클래스 주소 201.222.5.0이 주어졌을 때, 20개의 서브넷을 구성하고 서브넷당 5개의 호스트를 지정할 수 있도록 서브넷 마스크와 IP 주소를 할당하시오.
풀이
-
서브넷 마스크 계산
- C 클래스의 서브넷 마스크: /24 (255.255.255.0)
- 20개의 서브넷을 만들기 위해 필요한 비트 수는 5비트 (
2^n>=20,n=5) 2^5 = 32이므로 32개의 서브넷 만들 수 있음- 따라서 서브넷 마스크: /24 + 5 = /29 (255.255.255.248)
-
호스트 수 계산
2^n>=5,n=3- 따라서 서브넷 당 유효 호스트 수:
2^3-2= 6개 (네트워크/브로드캐스트 제외)
-
서브넷 할당
201.222.5.0을 2진수로 변환하면, 11001001.11011110.00000101.00000000- 각 서브넷은 8개의 IP 주소를 제공하며, 네트워크 주소와 브로드캐스트 주소를 제외한 6개가 유효 호스트 IP로 할당
-
따라서 서브넷 주소는 8개씩 증가하며 나누어짐
서브넷 번호 네트워크 주소 유효 호스트 시작 유효 호스트 끝 브로드캐스트 주소 1 201.222.5.0/29 201.222.5.1 201.222.5.6 201.222.5.7 2 201.222.5.8/29 201.222.5.9 201.222.5.14 201.222.5.15 … 31 201.222.5.240/29 201.222.5.241 201.222.5.246 201.222.5.247 32 201.222.5.248/29 201.222.5.249 201.222.5.254 201.222.5.255
-
결과
- 서브넷 마스크: /29 (255.255.255.248)
- 할당 가능한 호스트 IP 주소:
2^3-2= 6개 - 총 서브넷 수: 32개
- 하지만, 클래스 기반 IP 주소 할당에서는 서브넷 마스크에 따라 가능한 서브넷 수가 결정되며, 문제에서 요구한 20개의 서브넷만 사용하고 나머지 12개 서브넷은 사용되지 않는다.
5. IPv6
5.1 IPv6 주소
IPv4의 주소 부족 문제를 해결하기 위해 등장한 프로토콜이 IPv6이다.
- IPv6는 128비트 (16바이트)로 주소를 표현할 수 있고, 콜론(:)으로 구분된 8개 그룹의 16진수로 표기된다.
- 이론적으로 할당 가능한 IPv6 주소는
2^128개이다. (사실상 무한에 가까운 수 할당 가능) - IPv4 주소 표기:
192.168.1.1 - IPv6 주소 표기:
2001:0230:abcd:ffff:0000:0000:ffff:1111
5.2 IPv6 패킷의 핵심 필드
IPv6 패킷의 핵심 필드는 1)다음 헤더, 2)홉 제한, 3)송신지 IP 주소, 4)수신지 IP 주소 가 존재한다.
IPv6 패킷은 IPv4와는 다르게 간소화된 구조를 가지고 있다.

5.2.1 다음 헤더(next header)
상위 계층의 프로토콜 또는 확장 헤더를 가리키는 필드이다.
- 확장 헤더란?
- IPv6는 기본 헤더와 더불어 확장 헤더라는 추가 헤더를 가질 수 있다.
- 확장 헤더는 기본 헤더와 페이로드 데이터 사이에 위치한다.
- 마치 꼬리를 물듯 또 다른 확장 헤더를 가질 수 있다.


- 대표적인 확장 헤더
- 홉 간 옵션
- 수신지 옵션
- 라우팅
- 단편
- ESP
- …
여기서 IPv6의 단편화와 깊이 연관되어있는 단편 헤더에 대해 자세히 살펴보도록 하자.
5.2.2 IPv6의 단편화
IPv6는 단편화 확장 헤더를 통해 단편화가 이루어진다.
- 단편화 확장 헤더에도 다음 헤더 필드가 존재한다.
- 예약됨(reserved)과 예약(res) 필드는 0으로 설정되어 사용되지 않는다.
- 단편화 오프셋과 M 플래그, 식별자 필드를 갖는다.
- 단편화 오프셋: 전체 메시지에서 현재 단편화된 패킷의 위치(IPv4의 단편화 오프셋 필드와 유사)
- M 플래그: 1일 경우 더 많은 단편화 패킷이 있음을, 0일 경우 마지막 패킷을 의미(IPv4의 MF 플래그 필드와 유사)
- 식별자: 동일한 메시지에서부터 단편화된 패킷임을 식별(IPv4의 식별자 필드와 유사)

5.2.3 홉 제한(hop limit)
패킷의 수명을 나타내는 필드이다.
IPv4 패킷의 TTL 필드와 비슷하다.
5.2.4 송신지 IP 주소, 수신지 IP 주소
IPv6 주소를 통한 송수신지를 지정하는 필드이다.
6. 단편화를 피하는 방법
IP 단편화는 되도록 하지 않는 것이 좋다. 그 이유는 다음과 같다.
- 불필요한 트래픽 증가와 대역폭 낭비
- 쪼개진 IP 패킷들을 하나로 합치는 과정에서 발생하는 부하도 성능 저하 요소

실제로도 단편화는 자주 일어나지 않는다.
대부분 DF(Don’t Fragment) 비트가 세팅되어 있기 때문이다.
즉, IP 패킷을 주고받는 모든 노드가 “IP 단편화 없이 주고 받을 수 있는 최대 크기” 만큼만 전송해야 한다.
6.1 IPv4
- 단편화 가능:
- 경로 상에서 MTU보다 큰 패킷은 자동으로 단편화됨.
- 단편화 방지:
- 패킷을 송신하기 전, 경로 MTU(Path MTU)를 수동 또는 동적으로 확인하고 해당 크기에 맞게 패킷을 조정.
- IP 단편화 없이 주고 받을 수 있는 최대 크기를 경로 MTU(Path MTU) 라고 부름,
6.2 IPv6
- 단편화 제거:
- IPv6는 경로 상의 노드에서 단편화를 수행하지 않음.
- 대안:
- 전송 경로에서 MTU를 미리 계산하여 패킷 크기를 조정 후 전송.
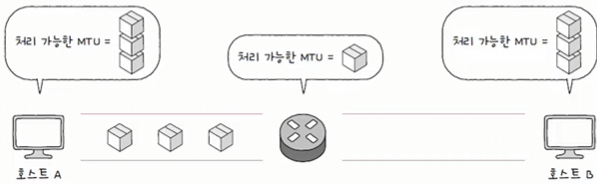
- 전송 경로에서 MTU를 미리 계산하여 패킷 크기를 조정 후 전송.
요약
- IPv4는 단편화를 지원하지만 경로 MTU 확인으로 피할 수 있음.
- IPv6는 단편화를 지원하지 않고 MTU를 계산하여 패킷 크기를 조정.
댓글남기기