
[OS] CPU 스케줄링
▶ CPU 스케줄링⭐
▷ 목적
- CPU가 쉬지 않고 최대한 일을 하도록 하기 위해 CPU 스케줄링을 한다!
- 멀티프로그래밍을 통해 CPU 효율을 극대화 ( *오버헤드를 최소화 )
- 프로세들에게 합리적으로 CPU 자원 배분(=CPU 스케줄링)
-
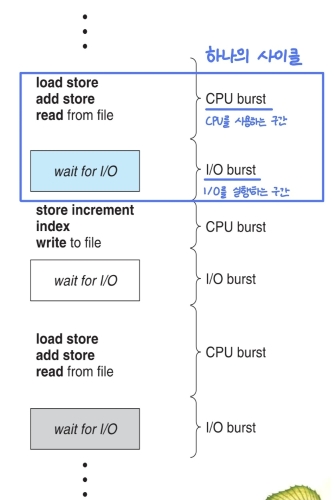
Burst (버스트)
- 어떤 현상이 짧은 시간 안에 집중적으로 일어나는 것을 의미
- ex. 수강신청
- CPU burst
- 프로세스가 CPU에서 연속적으로 CPU를 사용하는 시간 (job size)
- I/O burst
- 프로세스가 IO 작업을 요청하고, 그 결과를 기다리는 시간 (CPU 사용x)
- 즉, 프로세스는 CPU burst와 I/O burst가 번갈아가며 실행되는 것을 알 수 있다.
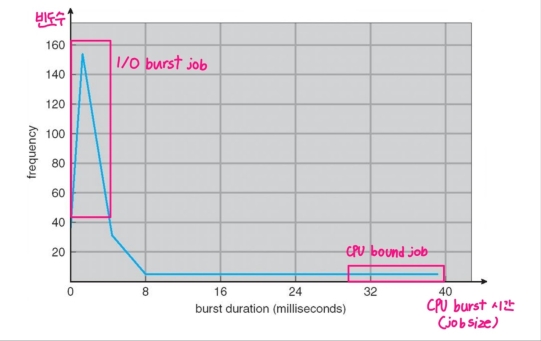
CPU-Burst Times 히스토그램
- I/O작업을 수행하는 빈도가 많아질수록 cpu burst시간이 짧아진다. (작은 job들이 많음)
- CPU Burst 시간이 많은지(= CPU Bound), 적은지(= IO Burst 시간이 많음 = IO Bound)에 따라 분류할 수 있다.
- CPU Burst가 많은 프로세스 = CPU를 많이 사용하는 프로세스 (동영상 편집 프로그램, 머신러닝 프로그램)
- I/O Burst가 많은 프로세스 = I/O를 많이 사용하는 프로세스 (백엔드 API 서버, 비디오 재생)
▷ CPU 스케줄러
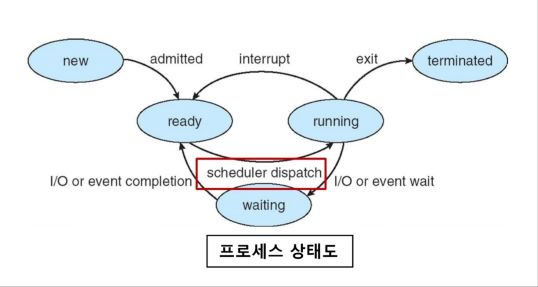
- CPU 스케줄러란?
- ready 상태인 여러 프로세스 중에서 다음 실행할 프로세스를 선택하여 running 상태로 만드는 것
- 즉, ready queue에서 프로세스를 선택하여 CPU에 할당
- 이러한 할당 과정을 dispatch라고 한다. 자세히 알고 싶다면 클릭하기!
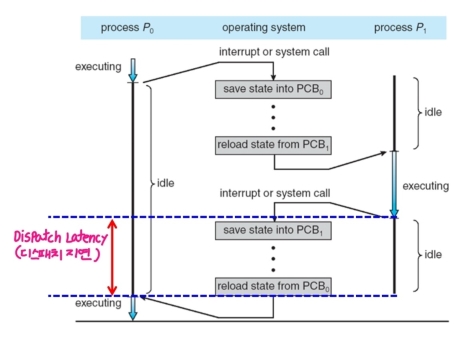
- 디스패치 지연 (Dispatch Latency)
- 디스패처가 현재 실행 중인 프로세스를 멈추고, 다른 프로세스를 실행하는 시간을 의미한다.
- 즉, Context Switching 시간을 의미
▷ CPU 스케줄링 결정 시점
- 프로세스의 상태가 변화함에 따라, CPU 스케줄링 결정이 일어나는 상황
- ① Running → Waiting
- ② Running → Ready
- ③ Waiting → Ready
- ④ New → Ready
- ⑤ Terminates
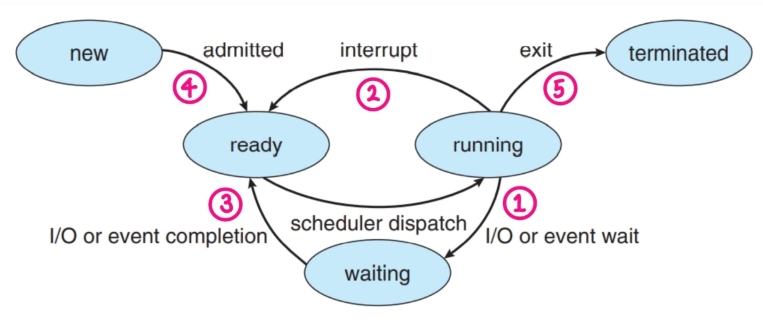
- Ready → Running 은?
- CPU 스케줄링 결정이 일어나지 않는다.
- 이미 정리되어 있는 Ready Queue에서 단순히 프로세스를 꺼내는 CPU로 할당시키는 것이기 때문이다.
▶ 선점 vs 비선점
| 구분 | 선점형 스케줄링 | 비선점 스케줄링 |
|---|---|---|
| 개념 | ① 가장 자원이 필요한 프로세스(우선순위 높음)에게 CPU를 분배하며, 자원을 강제로 빼앗아 다른 프로세스에 할당할 수 있는 스케줄링 방식 [ 새치기와 비슷한 개념 ] |
① 프로세스가 종료되거나 대기 상태에 접어들기 전까지 다른 프로세스가 끼어들 수 없는 스케줄링 방식 ② 하나의 프로세스가 자원 사용 독점 |
| 장점 | 하나의 프로세스의 자원 독점을 막고 골고루 배분 가능 | ① 선점형보다 문맥교환에 의한 오버헤드가 적다 ② 응답시간을 예상할 수 있다. |
| 단점 | 문맥 교환 과정에서 오버헤드 발생 | ① 자원 골고루 사용 불가 ② 당장 사용해야 하는 상황에서도 무작정 기다림 |
| 발생 경우 | 현재 실행중인 프로세스가 계속 실행될 수 있고 다른 준비된 프로세스를 실행할 수 있으므로 선택의 여지가 있음 => 선점 ① Running → Ready ② Waiting → Ready ③ New → Ready |
CPU가 아무 일도 하지 않아 반드시 새로운 프로세스를 실행해야 하므로 선택의 여지가 없음 => 비선점 ① Running → Waiting ② Terminates |
- ⚠️ 선점 동작 방식에서의 주의사항
- 공유하는 자료를 갱신하고 있는 동안 선점 당하면 문제가 생긴다.
- 커널 작업 중에 선점 당하면, 커널의 중요한 자료에 문제가 생길 수 있다.
- 중요한 운영체제 작업 중에는 인터럽트의 발생을 불허한다.
▶ 스케줄링 기준
스케줄링 기준
- CPU utilization (CPU 이용률)
- CPU를 최대한 일하게 한다.
- Throughput (처리량)
- 단위시간당 실행을 완료하는 프로세스들의 개수
- Turnaround time (총 처리 시간)
- 프로세스의 제출시간과 완료시간의 간격
- Ready Queue 대기시간 + CPU실행시간 + I/O 시간
- 제출시간: 프로세스가 Ready Queue에 들어온 시간
- 완료시간: 프로세스가 ‘Terminated’되거나, ‘Waiting을 거쳐 Ready’로 변경된 순간의 시간 ⇒ ‘I/O 시간’
- Waiting time (대기 시간)
- Ready Queue에서 대기하면서 보낸 시간의 합
- Response time (응답시간)
- 대화식 시스템에서 응답이 시작되는 데 까지 걸리는 시간
- 평균 응답시간이 짧아야 하고, 응답시간의 편차가 작아야 한다.
- ex. 터미널에 키보드로 A 입력시, A가 입력되었음을 시스템이 알아차리는데 걸리는 시간
- Burst time(실행 시간)
- CPU 할당 후 입출력을 요구할 때까지의 시간
스케줄링 알고리즘 최적화 기준
- Max CPU Utilization (CPU 이용률 최대화)
- Max Throughput (처리량 최대화)
- Min Turnaround Time (총 처리시간 최소화)
- Min Waiting Time (대기시간 최소화)
- Min Response Time (응답시간 최소화)
▶ CPU 스케줄링 종류
▷ FCFS (선입 선처리 스케줄링)
- FCFS(First Come, First Serve)
- Ready Queue에 먼저 도착한 프로세스 먼저 처리
- 비선점 방식의 스케줄링 (중간에 CPU를 뺏기지 않음, 공평성 보장)
- 호위 효과 (Convoy Effect)
- 긴 프로세스 뒤에 작은 프로세스가 있을때 모두 긴 작업을 대기해야 하는 상황
- 미국 옥수수🌽 트럭 등치 아저씨 생각하기… 30분 넘게 아무도 못 지나가
예시 ①
| process | Burst Time (연속사용시간) |
|---|---|
| P1 | 24 |
| P2 | 3 |
| P3 | 3 |
- 가정: Burst Time은 위와 같고, 프로세스가 순차적으로 도착(P1, P2, P3)
- [ 간트 차트 ]
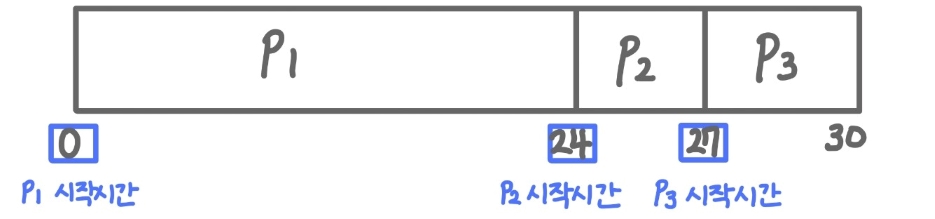
- 총 처리 시간 (Turnaround Time) → Burst Time의 합산 24 + 3 + 3 = 30
-
대기시간 (Wairing time) FCFS에서의 특정 프로세스 대기시간 = 특정 프로세스의 시작시간 P1 = 0, P2 = 24, P3 = 27 (24+3)
-
평균 대기시간 (Average waiting time) (0 + 24 + 27) / 3 = 17
- 예시 ①은, [ 호위효과(Convoy Effect)🌽가 발생한다! ]
예시 ②
| process | Burst Time (연속사용시간) |
|---|---|
| P1 | 24 |
| P2 | 3 |
| P3 | 3 |
-
가정: P2 , P3 , P1순으로 프로세스가 도착 [ 간트 차트 ]
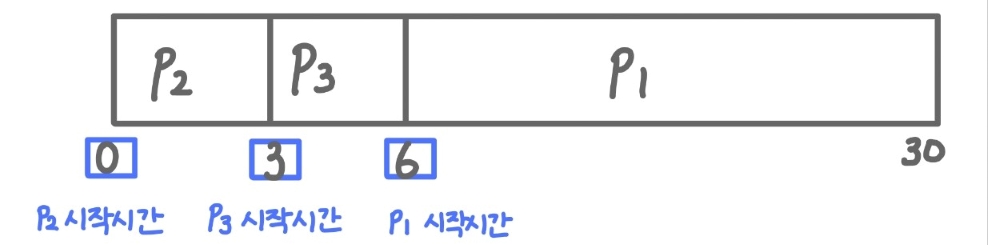
-
대기시간 (Waiting time) P1 = 6, P2 = 0, P3 = 3
- 평균 대기시간 (Average waiting time) (6 + 0 + 3) / 3 = 3
- 순서 조정만 했을 뿐인데 평균 대기 시간이 크게 감소한 것을 확인할 수 있다. (호위효과 발생 x)
-
▷ SJF (최단 작업 우선 스케줄링)
- SJF (Shortest Job First)
- 호위 효과를 방지하기 위해 Burst Time(CPU 이용시간)이 가장 짧은 프로세스부터 먼저 처리
- 비선점형 스케줄링 방식이라서 Burst Time이 긴 프로세스의 경우 기아 상태가 발생 할 수 있다.
- FCFS보다는 Waiting Time을 줄일 수 있다.
- 가장 적은 평균 대기 시간을 보장하는 효과적인 알고리즘이지만, 각 프로세스의 CPU Burst Time을 미리 알기가 힘들다. (시뮬레이션 해보지도 않았는데 모든 job들의 사이즈 알 수 없음.)
예시 ①
| process | Burst Time (연속사용시간) |
|---|---|
| P1 | 6 |
| P2 | 8 |
| P3 | 7 |
| P4 | 3 |
- [ 간트 차트 ]
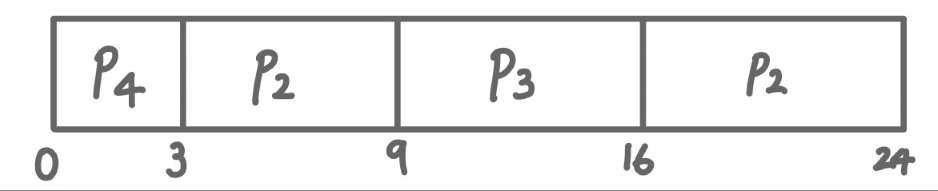
- 평균 대기 시간 (Average waiting time) (3 + 16 + 9 + 0) / 4 = 7
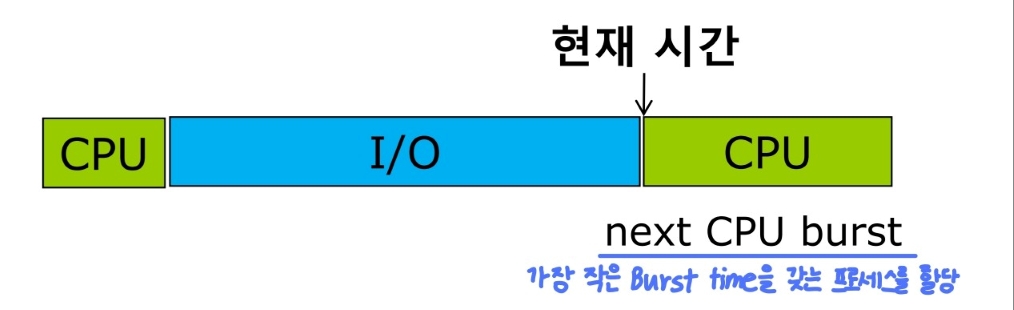
다음 CPU Burst Time 예측
-
SJF는 가장 좋은 스케줄링 방법이지만 CPU Burst Time을 미리 알 방법이 없다.
- 따라서, CPU Burst Time을 예측해야한다.
-
예측 방법 (
시험에 안나온다고 하심😄)- “다음 프로세스의 버스트 길이가 직전 프로세스의 버스트 길이와 비슷할 것이다.” 라는 가정을 통해 CPU의 Burst Time을 예측한다.


- “다음 프로세스의 버스트 길이가 직전 프로세스의 버스트 길이와 비슷할 것이다.” 라는 가정을 통해 CPU의 Burst Time을 예측한다.
▷ SRTF (최소잔여시간우선)⭐
- SRTF (Shortest-Remaining-Time-First)
- 선점형 SJF를 SRTF라고 한다.
- 즉, 현재 진행중인 프로세스를 중단시키고 CPU 점유시간이 짧게 남은 프로세스 처리를 가능하게 한다.
- 도착시간이 다른 것과 선점의 개념을 추가한다.
-
SRTF에서 Turnaround Time (총처리시간) 구하기
- 프로세스의 Turnaround Time = 완료시간 - 도착시간
-
SRTF에서 Waiting Time (대기시간) 구하기
- 프로세스의 Waiting Time = Turnaround Time - Burst Time
-
예시
process Arrival Time Burst Time (연속사용시간) P1 0 8 P2 1 4 P3 2 9 P4 3 5 - [ 간트 차트 ]
❗현재 들어온 프로세스의 Burst time이 현재 실행중인 프로세스의 Burst time보다 작을 때만 선점이 일어난다.
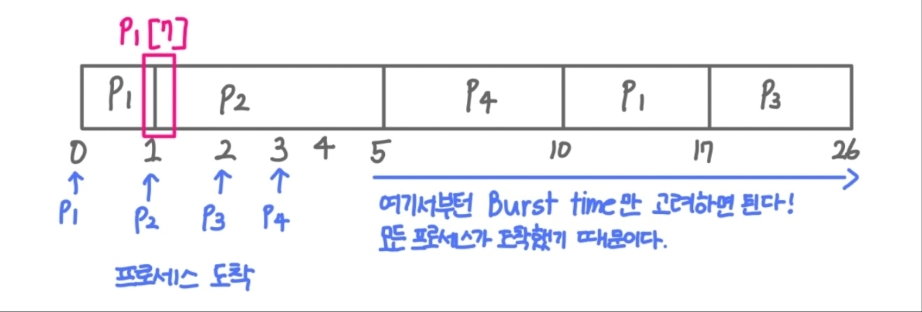
- [ 간트 차트 ]
❗현재 들어온 프로세스의 Burst time이 현재 실행중인 프로세스의 Burst time보다 작을 때만 선점이 일어난다.
- 반환 시간 (Turnaround Time)
- P1 Turnaround Time : 17 - 0 = 17
- P2 Turnaround Time : 5 - 1 = 4
- P3 Turnaround Time : 26 - 2 = 24
- P4 Turnaround Time : 10 - 3 = 7
- 대기 시간 (Waiting Time)
- P1 Waiting Time : 17 - 8 = 9
- P2 Waiting Time : 4 - 4 = 0
- P3 Waiting Time : 24 - 9 = 15
- P4 Waiting Time : 7 - 5 = 2
- 총 처리 시간 (Turnaround Time)
- 8 + 4 + 9 + 5 = 26ms
- 평균 대기 시간 (Average waiting time)
- (9 + 0 + 15 + 2) / 4 = 6.5 (msec)
▷ PS (우선순위 스케줄링)
- PS (Priority Scheduling)
- 각 프로세스에게 숫자로 우선순위를 표기하고, 가장 높은 우선순위를 가진 프로세스부터 실행하는 방식이다.
- SJF도 우선순위 스케줄링의 일종이다.
- Priority Scheduling 종류
- Preemptive(선점형) Priority Scheduling
- 새로 도착한 프로세스의 우선순위가 현재 실행되는 프로세스의 우선순위보다 높으면 CPU를 선점한다.
- Priority는 낮을수록 좋다. (but 시스템 따라 다를 수 있음)
- Nonpreemptive(비선점형) Priority Scheduling
- 우선순위가 가장 높은 프로세스를 Ready Queue의 맨 앞에 넣는다.
- Preemptive(선점형) Priority Scheduling
- 우선순위는 Burst Time(길이)에 반비례한다.
- 긴 Burst ⇒ 우선순위가 낮음
- 짧은 Burst ⇒ 우선순위가 높음
- 문제점⭐
- 기아 상태(Starvation)
- 낮은 우선순위의 프로세스가 계속해서 대기만 하는 상태
- 내가 size가 크다고 계속 우선순위가 높은 애들이 새치기를 해대면 굶어 죽을거야😭😇
- 기아 상태(Starvation)
- 해결 방안⭐
- 에이징(Aging) 기법
- 오랫동안 대기한 프로세스의 우선순위를 점차 높이는 방식
- 나이 먹으면 우선순위 증가됨
- 에이징(Aging) 기법
예시
| process | Burst Time (연속사용시간) | Priority |
|---|---|---|
| P1 | 10 | 3 |
| P2 | 1 | 1 |
| P3 | 2 | 4 |
| P4 | 1 | 5 |
| P5 | 5 | 2 |
- [ 간트 차트 ]
❗단순히 우선순위가 가장 높은 순서대로 실행된다.

- 평균 대기 시간 (Average waiting time)
- 8.2 (msec)
▷ RR (라운드 로빈)⭐
-
RR (Round Robin)
- 시분할 시스템을 위해 설계된 선점형 스케줄링 방식
- 정해진 타임 슬라이스만큼의 시간동안 돌아가며 CPU를 이용한다.
- 시간할당량(CPU 시간) = q (Quantum)
-
시간 q를 모두 사용했음에도 프로세스가 완료되지 않았다면, 실행 중이던 프로세스가 선점(새치기)당하여 준비완료 큐의 끝에 가게 된다. -> 문맥 교환 발생
- 예시
- 준비완료 큐에 5개의 프로세스 존재하고, q(시간할당량)가 20밀리초이면, 각 프로세스는 매 100밀리초마다 최대 20밀리초를 할당 받는다.
시간할당량(q)에 따른 성능
-
q가 너무 클 때
- FCFS와 동일하게 동작한다. (어떤 job이 들어와도 제시간에 끝남)
- Convoy Effect(호위 효과) 가 발생할 수 있다.
-
q가 너무 작을 때
- Context Switching 이 매우 빈번하게 일어난다.
- 따라서 문맥 교환 발생이 많이 발생 -> 오버헤드 발생
-
정리
- 시간할당량(q)는 보통 10ms ~ 100ms로 설정한다.
- 그리고 Context Switching 시 오버헤드는 10마이크로초 이내여야 한다.
예시
- 가정: Time Quantum = 4
| process | Burst Time (연속사용시간) |
|---|---|
| P1 | 24 |
| P2 | 3 |
| P3 | 3 |
- [ 간트 차트 ]

- Time Quantum(q)와 Context Switching 간의 관계
- time Quantum에 따라 Context Switching 개수가 달라진다!
-
가정: Burst Time = 10
-
q가 12일 때, Context Switching이 일어나지 않는다.

-
q가 6일 때, Context Switching 1번 일어난다.

-
q가 1일 때, Context Switching 9번 일어난다.

-
📎참조
- 성결대학교 강영명 교수님 운영체제 (2023)
- https://litong.tistory.com/18
- https://melonicedlatte.com/2022/04/30/162100.html
- https://taegyunwoo.github.io/os/OS_CPU_Scheduling
- https://velog.io/@hosunghan0821/CPU-Bound-IO-Bound
- https://m.blog.naver.com/zxwnstn/221818143358
- https://engineerinsight.tistory.com/285
- https://hongchangsub.com/cpu-scheduling-fcfs-sjf-srtf/
댓글남기기